Raspberry Pi 3 Model BでNginx+PostgreSQL+Django環境構築
どうも,筆者です.
前回,Docker のインストールを行った. workspacememory.hatenablog.com
今回は,Dockerfile と docker-compose.yml を使って Nginx+PostgreSQL +Django 環境を構築する. 参考1 参考2
構成
.
│ docker-compose.yml
│
├─django
│ Dockerfile
│ requirements.txt
│ uwsgi.ini
│
├─logs
│ access.log
│ error.log
│ uwsgi.log
│
├─nginx
│ │ Dockerfile
│ │
│ ├─cache
│ ├─conf
│ │ default.conf
│ │ nginx.conf
│ │ uwsgi_params
│ │
│ └─dockerApp
│ nginx
│ wakeup.sh
│
├─postgresql
│ Dockerfile
│
├─src
│ │ manage.py
│ │
│ └─membership_system
│ │ settings.py
│ │ urls.py
│ │ wsgi.py
│ │ __init__.py
│ │
│ └─__pycache__
│ settings.cpython-36.pyc
│ urls.cpython-36.pyc
│ __init__.cpython-36.pyc
│
└─static
└─admin
├─css
│ │ autocomplete.css
│ │ base.css
│ │ changelists.css
│ │ dashboard.css
│ │ fonts.css
│ │ forms.css
│ │ login.css
│ │ responsive.css
│ │ responsive_rtl.css
│ │ rtl.css
│ │ widgets.css
│ │
│ └─vendor
│ └─select2
│ LICENSE-SELECT2.md
│ select2.css
│ select2.min.css
│
├─fonts
│ LICENSE.txt
│ README.txt
│ Roboto-Bold-webfont.woff
│ Roboto-Light-webfont.woff
│ Roboto-Regular-webfont.woff
│
├─img
│ │ calendar-icons.svg
│ │ icon-addlink.svg
│ │ icon-alert.svg
│ │ icon-calendar.svg
│ │ icon-changelink.svg
│ │ icon-clock.svg
│ │ icon-deletelink.svg
│ │ icon-no.svg
│ │ icon-unknown-alt.svg
│ │ icon-unknown.svg
│ │ icon-yes.svg
│ │ inline-delete.svg
│ │ LICENSE
│ │ README.txt
│ │ search.svg
│ │ selector-icons.svg
│ │ sorting-icons.svg
│ │ tooltag-add.svg
│ │ tooltag-arrowright.svg
│ │
│ └─gis
│ move_vertex_off.svg
│ move_vertex_on.svg
│
└─js
│ actions.js
│ actions.min.js
│ autocomplete.js
│ calendar.js
│ cancel.js
│ change_form.js
│ collapse.js
│ collapse.min.js
│ core.js
│ inlines.js
│ inlines.min.js
│ jquery.init.js
│ popup_response.js
│ prepopulate.js
│ prepopulate.min.js
│ prepopulate_init.js
│ SelectBox.js
│ SelectFilter2.js
│ timeparse.js
│ urlify.js
│
├─admin
│ DateTimeShortcuts.js
│ RelatedObjectLookups.js
│
└─vendor
├─jquery
│ jquery.js
│ jquery.min.js
│ LICENSE-JQUERY.txt
│
├─select2
│ │ LICENSE-SELECT2.md
│ │ select2.full.js
│ │ select2.full.min.js
│ │
│ └─i18n
│ ar.js
│ az.js
│ bg.js
│ ca.js
│ cs.js
│ da.js
│ de.js
│ el.js
│ en.js
│ es.js
│ et.js
│ eu.js
│ fa.js
│ fi.js
│ fr.js
│ gl.js
│ he.js
│ hi.js
│ hr.js
│ hu.js
│ id.js
│ is.js
│ it.js
│ ja.js
│ km.js
│ ko.js
│ lt.js
│ lv.js
│ mk.js
│ ms.js
│ nb.js
│ nl.js
│ pl.js
│ pt-BR.js
│ pt.js
│ ro.js
│ ru.js
│ sk.js
│ sr-Cyrl.js
│ sr.js
│ sv.js
│ th.js
│ tr.js
│ uk.js
│ vi.js
│ zh-CN.js
│ zh-TW.js
│
└─xregexp
LICENSE-XREGEXP.txt
xregexp.js
xregexp.min.js
docker-compose.yml
docker-compose コマンドを実行する際に利用するdocker-compose.ymlファイルを以下に示す.
version: '3.4' volumes: # DBデータの永続化 postgresql.volume: name: postgresql.volume services: # nginxの設定 nginx: # ビルド対象 build: context: ./nginx # Dockerfile名 dockerfile: Dockerfile # イメージ名 image: custom_nginx # コンテナ名 container_name: nginx restart: always # 環境変数の設定 environment: TZ: Asia/Tokyo # ポートの設定(DockerfileのEXPOSEとそろえる) ports: - "18082:18082" # nginxのconfigファイル等の関連付け volumes: - ./nginx/conf/default.conf:/etc/nginx/conf.d/default.conf:ro - ./nginx/cache:/var/cache/nginx - ./logs/access.log:/var/log/nginx/access.log - ./logs/error.log:/var/log/nginx/error.log - ./static:/static:ro # 依存関係の記述 depends_on: - django # DBの設定 db: # ビルド対象 build: context: ./postgresql # Dockerfile名 dockerfile: Dockerfile # イメージ名 image: custom_postgres # コンテナ名 container_name: postgresql restart: always environment: POSTGRES_DB: djangodb POSTGRES_USER: postgres POSTGRES_PASSWORD: 1234 POSTGRES_INITDB_ARGS: "--encoding=UTF-8 --locale=ja_JP.UTF-8" # ポートの設定(外部には公開しない) expose: - "5432" # 設定ファイルとデータ格納先の関連付け volumes: - postgresql.volume:/var/lib/postgresql/data # djangoの設定 django: # ビルド対象 build: context: ./django # Dockerfile名 dockerfile: Dockerfile # イメージ名 image: django_with_uwsgi # コンテナ名 container_name: django restart: always # 利用するアプリの関連付け volumes: - ./src:/code - ./static:/static:ro - ./logs/uwsgi.log:/var/log/uwsgi.log working_dir: /code # ポートの設定(外部には公開しない) expose: - "8081" # 依存関係の記述 depends_on: - db
Django の設定
ここでは,Django の設定内容について説明する.
Dockerfile
Django のイメージファイルを作成する際に利用する Dockerfile を以下に示す.
FROM resin/raspberry-pi-alpine:3.6 # Pythonで利用する環境変数の設定 # バイナリレイヤ下での標準出力とエラー出力を抑制 ENV PYTHONUNBUFFERED 1 # アプリケーション用のディレクトリの作成 RUN mkdir /code && mkdir /static # requirements.txtを追加 ADD requirements.txt /code/ # パッケージ群のインストール RUN apk update \ # タイムゾーンの設定 && apk add --no-cache bash tzdata pcre-dev \ && cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime \ # PostgreSQL用のライブラリをインストール && apk add --no-cache postgresql-dev \ # 一時的に必要なパッケージをインストール && apk add --no-cache \ --virtual .build-temp shadow \ gcc libc-dev linux-headers \ musl-dev python3-dev libffi-dev libressl-dev \ # Python3をインストール && apk add --no-cache python3 \ # pip install && python3 -m ensurepip \ && rm -r /usr/lib/python*/ensurepip \ && pip3 install --upgrade pip setuptools \ # requirements.txtに記載されたライブラリ群をインストール && pip3 install -r /code/requirements.txt \ # シンボリックリンク && if [[ ! -e /usr/bin/python ]]; then ln -sf /usr/bin/python3 /usr/bin/python; fi \ # ユーザとグループの追加(Nginxと連動するため統一) && useradd -s /sbin/nologin -M -d /dev/null nginx \ # 一時的に必要だったパッケージを削除 && apk del .build-temp \ && rm -rf /root/.cache /var/cache/apk/* # uWSGIの設定ファイルをコピー COPY ./uwsgi.ini /uwsgi.ini # ログ出力先の設定 RUN echo -n > /var/log/uwsgi.log # 内部で利用するポートの設定 EXPOSE 8081 # コマンド実行 CMD ["uwsgi", "--ini", "/uwsgi.ini", "--logto", "/var/log/uwsgi.log"]
Django で利用する設定ファイル
Django の環境構築時に利用する設定ファイルを以下に示す.
requirements.txt
Django==2.0.7 uwsgi==2.0.17 psycopg2==2.8.2 psycopg2-binary==2.8.2 hashids==1.2.0 django-betterforms==1.2 django-bootstrap4==0.0.6 django-crispy-forms==1.7.2 django-filter==2.1.0 django-extra-views==0.11.0 django-widgets-improved==1.5.0
uwsgi.ini
[uwsgi] user = nginx uid = nginx gid = nginx chdir = /code module = membership_system.wsgi:application master = true enable-threads = true thunder-lock = true max-requests = 1000 processes = 1 threads = 2 vacuum = true socket = :8081 close-on-exec = true die-on-term = true
docker-compose の設定(対応箇所の抜粋)
対応する docker-compose の設定情報を以下に示す.今回は,8081 番のポートで待ち受ける.このポートは外部に公開しない.
# djangoの設定 django: # ビルド対象 build: context: ./django # Dockerfile名 dockerfile: Dockerfile # イメージ名 image: django_with_uwsgi # コンテナ名 container_name: django restart: always # 利用するアプリの関連付け volumes: - ./src:/code - ./static:/static:ro - ./logs/uwsgi.log:/var/log/uwsgi.log working_dir: /code # ポートの設定(外部には公開しない) expose: - "8081" # 依存関係の記述 depends_on: - db
PostgreSQL の設定
ここでは,PostgreSQL の設定内容について説明する. 参考
Dockerfile
Django のイメージファイルを作成する際に利用する Dockerfile を以下に示す.
FROM postgres:latest RUN localedef -i ja_JP -c -f UTF-8 -A /usr/share/locale/locale.alias ja_JP.UTF-8 ENV LANG ja_JP.UTF-8
docker-compose の設定(対応箇所の抜粋)
対応する docker-compose の設定情報を以下に示す.今回は,5432 番のポートで待ち受ける.このポートは外部に公開しない.
volumes: # DBデータの永続化 postgresql.volume: name: postgresql.volume
# DBの設定 db: # ビルド対象 build: context: ./postgresql # Dockerfile名 dockerfile: Dockerfile # イメージ名 image: custom_postgres # コンテナ名 container_name: postgresql restart: always environment: POSTGRES_DB: djangodb POSTGRES_USER: postgres POSTGRES_PASSWORD: 1234 POSTGRES_INITDB_ARGS: "--encoding=UTF-8 --locale=ja_JP.UTF-8" # ポートの設定(外部には公開しない) expose: - "5432" # 設定ファイルとデータ格納先の関連付け volumes: - postgresql.volume:/var/lib/postgresql/data
また,ユーザ名とパスワードは以下のようにした.そのまま利用する際は,適宜変更すること.
| 項目 | 内容 |
|---|---|
| ユーザ名 | postgres |
| パスワード | 1234 |
Nginx の設定
ここでは,Nginx の設定内容について説明する.
Dockerfile
Nginx のイメージファイルを作成する際に利用する Dockerfile を以下に示す.
FROM resin/raspberry-pi-alpine:3.6 # Nginxのバージョン指定 ENV NGINX_VERSION 1.14.0 # Nginxのインストール RUN apk update \ && apk add --no-cache pcre-dev openssl-dev bash shadow tzdata \ && useradd -s /sbin/nologin -M -d /dev/null nginx \ && cp /usr/share/zoneinfo/Asia/Tokyo /etc/localtime \ && apk add --no-cache --virtual build-dependencies build-base curl \ && curl -SLO http://nginx.org/download/nginx-${NGINX_VERSION}.tar.gz \ && tar xzvf nginx-${NGINX_VERSION}.tar.gz \ && cd nginx-${NGINX_VERSION} \ && ./configure \ --user=nginx \ --group=nginx \ --with-http_ssl_module \ --with-http_realip_module \ --with-http_addition_module \ --with-http_sub_module \ --with-http_dav_module \ --with-http_flv_module \ --with-http_mp4_module \ --with-http_gunzip_module \ --with-http_gzip_static_module \ --with-http_random_index_module \ --with-http_secure_link_module \ --with-http_stub_status_module \ --with-http_auth_request_module \ --with-threads \ --with-stream \ --with-stream_ssl_module \ --with-http_slice_module \ --with-mail \ --with-mail_ssl_module \ --with-file-aio \ --with-http_v2_module \ --prefix=/usr/share/nginx \ --sbin-path=/usr/local/sbin/nginx \ --conf-path=/etc/nginx/nginx.conf \ --pid-path=/var/run/nginx.pid \ --http-log-path=/var/log/nginx/access.log \ --error-log-path=/var/log/nginx/error.log \ && make \ && make install \ && echo -n > /var/log/nginx/access.log \ && echo -n > /var/log/nginx/error.log \ && cd / \ && apk del build-dependencies shadow \ && rm -rf nginx-${NGINX_VERSION} nginx-${NGINX_VERSION}.tar.gz /var/cache/apk/* # static directory for django RUN mkdir /static # volumeの設定 VOLUME /var/cache/nginx # 設定の書き換え COPY ./conf/nginx.conf /etc/nginx/nginx.conf COPY ./conf/uwsgi_params /etc/nginx/uwsgi_params # 内部で利用するポートの設定 EXPOSE 18082 # 利用するシェルスクリプトをコンテナに配置 COPY ./dockerApp/wakeup.sh /wakeup.sh COPY ./dockerApp/nginx /etc/init.d/nginx RUN chmod a+x /wakeup.sh /etc/init.d/nginx # entrypoint: 何もしない ENTRYPOINT [""] # コマンド実行 CMD ["/wakeup.sh"]
また,利用する shell script を以下に示す.
nginx
#!/bin/bash set -e PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin DESC="nginx daemon" NAME=nginx DAEMON=/usr/local/sbin/${NAME} SCRIPTNAME=/etc/init.d/${NAME} # if daemon file not found, exit script. test -x ${DAEMON} || exit 0 d_start() { ${DAEMON} || echo -n " already running" } d_stop() { ${DAEMON} -s quit || echo -n " not running" } d_reload() { ${DAEMON} -s reload || echo -n " could not reload" } case "$1" in start) echo -n "Starting ${DESC}: ${NAME}" d_start sleep 3 echo "." ;; stop) echo -n "Stopping ${DESC}: ${NAME}" d_stop sleep 3 echo "." ;; reload) echo -n "Reloading ${DESC}: configuration..." d_reload sleep 3 echo "reloaded." ;; restart) echo -n "Restarting ${DESC}: ${NAME}" d_stop sleep 5 d_start echo "." ;; *) echo "Usage: ${SCRIPTNAME} {start|stop|restart|reload}" >&2 exit 3 ;; esac exit 0
wakeup.sh
#!/bin/bash # Nginx start /etc/init.d/nginx start # hook SIGTERM trap_TERM() { echo SIGTERM ACCEPTED. exit 0 } trap 'trap_TERM' TERM # loop while : do sleep 5 done
uWSGI の設定ファイル
Nginx で受けたリクエストを Django に投げる際の uWSGI の設定ファイルを以下に示す.
uwsgi_params
uwsgi_param QUERY_STRING $query_string; uwsgi_param REQUEST_METHOD $request_method; uwsgi_param CONTENT_TYPE $content_type; uwsgi_param CONTENT_LENGTH $content_length; uwsgi_param REQUEST_URI $request_uri; uwsgi_param PATH_INFO $document_uri; uwsgi_param DOCUMENT_ROOT $document_root; uwsgi_param SERVER_PROTOCOL $server_protocol; uwsgi_param REQUEST_SCHEME $scheme; uwsgi_param HTTPS $https if_not_empty; uwsgi_param REMOTE_ADDR $remote_addr; uwsgi_param REMOTE_PORT $remote_port; uwsgi_param SERVER_PORT $server_port; uwsgi_param SERVER_NAME $server_name;
Nginx の設定ファイル
Nginx のコンフィグファイルを以下に示す.
nginx.conf
# user nginx; worker_processes 1; error_log /var/log/nginx/error.log warn; pid /var/run/nginx.pid; events { worker_connections 1024; } http { include /etc/nginx/mime.types; default_type application/octet-stream; log_format main '$remote_addr - $remote_user [$time_local] "$request" ' '$status $body_bytes_sent "$http_referer" ' '"$http_user_agent" "$http_x_forwarded_for"'; access_log /var/log/nginx/access.log main; server_names_hash_bucket_size 64; sendfile on; keepalive_timeout 65; include /etc/nginx/conf.d/*.conf; }
default.conf
# the upstream component nginx needs to connect to upstream call_django { ip_hash; server django:8081; } # configuration of the server server { listen 18082; server_name _; server_tokens off; charset utf-8; access_log /var/log/nginx/access.log combined; error_log /var/log/nginx/error.log error; # max upload size client_max_body_size 64M; # adjust to taste location /static { alias /static; } # Finally, send all non-media requests to the Django server. location / { # avoid requests that are neither GET nor POST if ( $request_method !~ ^(GET|POST)$ ) { return 444; } # setting include /etc/nginx/uwsgi_params; # the uwsgi_params file you installed uwsgi_pass call_django; } }
docker-compose の設定(対応箇所の抜粋)
対応する docker-compose の設定情報を以下に示す.今回は,18082 番のポートで待ち受ける.
nginx: # ビルド対象 build: context: ./nginx # Dockerfile名 dockerfile: Dockerfile # イメージ名 image: custom_nginx # コンテナ名 container_name: nginx restart: always # 環境変数の設定 environment: TZ: Asia/Tokyo # ポートの設定(DockerfileのEXPOSEとそろえる) ports: - "18082:18082" # nginxのconfigファイル等の関連付け volumes: - ./nginx/conf/default.conf:/etc/nginx/conf.d/default.conf:ro - ./nginx/cache:/var/cache/nginx - ./logs/access.log:/var/log/nginx/access.log - ./logs/error.log:/var/log/nginx/error.log - ./static:/static:ro # 依存関係の記述 depends_on: - django
Docker Image 作成
Docker Image 作成のため,下記を実行する.
docker-compose build
log ファイルの作成
実行ログを記録するための log ファイルを作成する.
touch logs/uwsgi.log logs/access.log logs/error.log
Django のプロジェクトを作成
Django のプロジェクトを作成するため,下記のコマンドを実行する. 参考
# コンテナの作成 docker-compose up -d # django のコンテナに入る docker exec -it django bash # プロジェクトの作成 django-admin startproject membership_system . # コンテナから抜ける exit # 所有者の変更 sudo chown pi:pi -R src/
Django の設定
setting.py の編集
setting.py を修正する.
修正前
ALLOWED_HOSTS = [] # Database # https://docs.djangoproject.com/en/2.0/ref/settings/#databases DATABASES = { 'default': { 'ENGINE': 'django.db.backends.sqlite3', 'NAME': os.path.join(BASE_DIR, 'db.sqlite3'), } }
修正後
ALLOWED_HOSTS = ['localhost'] # Database # https://docs.djangoproject.com/en/2.0/ref/settings/#databases # 修正 DATABASES = { 'default': { 'ENGINE': 'django.db.backends.postgresql_psycopg2', 'NAME': 'djangodb', 'USER': 'postgres', 'PASSWORD': '1234', 'HOST': 'db', 'PORT': 5432, } }
マイグレーションの実行
下記のコマンドを実行する.
docker exec -it django bash # コンテナ内で作業 ./manage.py makemigrations ./manage.py migrate ./manage.py createsuperuser # いい感じに設定する #Username (leave blank to use 'root'): admin #Email address: admin@localhost #Password: #Password (again): # コンテナから抜ける exit
ページに接続する
ブラウザを開いて下記を入力する.「The install worked successfully! Congratulations!」が表示されれば成功.
http://(ホスト名orIPアドレス):18082
その他設定
タイムゾーンや言語,静的ファイルの設定を行う.
変更前
# Internationalization # https://docs.djangoproject.com/en/2.0/topics/i18n/ LANGUAGE_CODE = 'en_US' TIME_ZONE = 'UTC' USE_I18N = True USE_L10N = True USE_TZ = True # Static files (CSS, JavaScript, Images) # https://docs.djangoproject.com/en/2.0/howto/static-files/ STATIC_URL = '/static/'
変更後
# Internationalization
# https://docs.djangoproject.com/en/2.0/topics/i18n/
LANGUAGE_CODE = 'ja-JP'
TIME_ZONE = 'Asia/Tokyo'
USE_I18N = True
USE_L10N = True
USE_TZ = True
# Static files (CSS, JavaScript, Images)
# https://docs.djangoproject.com/en/2.0/howto/static-files/
STATIC_URL = '/static/'
STATIC_ROOT = '/static'
# static フォルダの読み込み専用を取り外す volumes: - ./src:/code # - ./static:/static:ro - ./static:/static - ./logs/uwsgi.log:/var/log/uwsgi.log working_dir: /code # コンテナの作り直し docker rm -f $(docker ps -aq) # コンテナの作成 docker-compose up -d docker exec -it django bash # コンテナ内で作業 ./manage.py collectstatic # コンテナから抜ける exit
Raspberry Pi 3 Model BにDocker導入
どうも,筆者です.
久しぶりの更新となる.
目的
Raspberry Pi 3 Model B に Docker を導入し,Nginx,MySQL,django を用いて,名簿作成システムを構築する.
実施内容
今回は,Raspberry Pi 3 Model B で下記の設定を行う.
- Docker のインストール
- Docker-Compose のインストール
Dockerのインストール
Raspberry Pi 3 Model B の環境を以下に示す.
cat /etc/os-release #PRETTY_NAME="Raspbian GNU/Linux 8 (jessie)" #NAME="Raspbian GNU/Linux" #VERSION_ID="8" #VERSION="8 (jessie)" #ID=raspbian #ID_LIKE=debian #HOME_URL="http://www.raspbian.org/" #SUPPORT_URL="http://www.raspbian.org/RaspbianForums" #BUG_REPORT_URL="http://www.raspbian.org/RaspbianBugs"
下記のコマンドで Docker をインストールする. 参考サイト
# Docker のインストール sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates curl gnupg2 software-properties-common curl -fsSL https://download.docker.com/linux/debian/gpg | sudo apt-key add - sudo apt-key fingerprint 0EBFCD88 echo "deb [arch=armhf] https://download.docker.com/linux/debian $(lsb_release -cs) stable" | sudo tee /etc/apt/sources.list.d/docker.list sudo apt-get update sudo apt-get install -y docker-ce # バージョンチェック(実行にはroot権限が必要) sudo docker version # 出力例 #Client: # Version: 18.06.3-ce # API version: 1.38 # Go version: go1.10.3 # Git commit: d7080c1 # Built: Wed Feb 20 02:48:01 2019 # OS/Arch: linux/arm # Experimental: false # #Server: # Engine: # Version: 18.06.3-ce # API version: 1.38 (minimum version 1.12) # Go version: go1.10.3 # Git commit: d7080c1 # Built: Wed Feb 20 02:43:39 2019 # OS/Arch: linux/arm # Experimental: false # ユーザを docker グループに追加(root権限が不要になる) sudo usermod -aG docker ${USER} # 一度ログアウトし,再度ログイン exit ### ログイン処理 ### # 再度,バージョンを確認 docker version
Docker-Compose のインストール
下記のコマンドで,Docker-Compose のインストールを実施する. 参考サイト
# git のインストール sudo apt-get install -y git # compose を clone git clone https://github.com/docker/compose.git # compose のインストール cd compose git checkout bump-1.23.2 # ブランチの変更 sed -i -e 's:^VENV=/code/.tox/py36:VENV=/code/.venv; python3 -m venv $VENV:' script/build/linux-entrypoint sed -i -e '/requirements-build.txt/ i $VENV/bin/pip install -q -r requirements.txt' script/build/linux-entrypoint docker build -t docker-compose:armhf -f Dockerfile.armhf . # しばらく待つ docker run --rm --entrypoint="script/build/linux-entrypoint" -v $(pwd)/dist:/code/dist -v $(pwd)/.git:/code/.git "docker-compose:armhf" sudo cp dist/docker-compose-Linux-armv7l /usr/local/bin/docker-compose sudo chown root:root /usr/local/bin/docker-compose sudo chmod 0755 /usr/local/bin/docker-compose docker-compose version #docker-compose version 1.23.2, build 1110ad01 #docker-py version: 3.6.0 #CPython version: 3.6.8 #OpenSSL version: OpenSSL 1.1.0j 20 Nov 2018 # イメージの削除 docker rmi $(docker images | grep docker-compose | awk '{print $3;}')
これで,Docker と Docker-Compose が導入できた.次は,Nginx,PostgreSQL,django のイメージの構築を行う.
次回
音声認識による赤外線機器の操作 その 7【全体制御編】
どうも,筆者です.
前回までで,認識した単語の解析まで行えるようになった.後は,選択した単語に対応する応答メッセージ(音声)を流しつつ,赤外線信号を送信すればよい.
前回までの記事は以下にある.
workspacememory.hatenablog.com
今回の対象
今回の実装対象を以下に示す.

実装対象一覧
実装するクラスを以下に示す.
- audioPlayer.py(応答メッセージ再生用)
- getWeather.py(天気予報取得用)
- voiceRecognition.py(音声認識用,メイン部分)
これらを順に実装する.
audioPlayer
音声再生には,Linux の aplay コマンドを利用する.「audioPlayer.py」の実装を以下に示す.
~/juliusKit $ touch audioPlayer.py ~/juliusKit $ vim audioPlayer.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # audioPlayer.py import subprocess as sb from VR_ConstClass import CONST_CLASS class audioClass(): def __init__(self): self.__audioFile = '' self.__process = sb.Popen(['/bin/echo', '0.001'], shell=True, stdout=sb.DEVNULL, stderr=sb.DEVNULL) self.__process.communicate() def setAudioFile(self, audio_file): self.__audioFile = audio_file def audioExitHandler(self): if self.__process.poll() is None: self.__process.terminate() def playAudio(self): if self.__audioFile == '': return self.audioExitHandler() useCmd = ['/usr/bin/aplay', CONST_CLASS.WAVE_DIR + self.__audioFile] self.__process = sb.Popen(useCmd, stdout=sb.DEVNULL, stderr=sb.DEVNULL)
getWeather
天気予報の取得には,Weather Hacks API を利用する.使い方は,以下のサイトを参考にした.
また,受信した情報を読み上げたいと考えたため,「Open JTalk」を利用して音声再生を行った.ここだけ,天気予報受信→再生という流れを取っているため,非同期で処理できていない.インストール方法は以下を参考にした.
インストール後,実装したコードを以下に示す.ファイル名を「getWeather.py」として保存した.
~/juliusKit $ touch getWeather.py ~/juliusKit $ vim getWeather.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # getWeather.py import requests import subprocess as sb from VR_ConstClass import CONST_CLASS class weatherClass(): def __init__(self): self.__url = 'http://weather.livedoor.com/forecast/webservice/json/v1' self.__city = 130010 self.__titleStr = 'title' self.__loopStr = 'forecasts' self.__dateStr = 'date' self.__telopStr = 'telop' self.__dicDir = '/usr/local/share/openJTalk/dic/' self.__voiceFile = '/usr/local/share/openJTalk/voice/mei_normal.htsvoice' self.__process = sb.Popen(['/bin/echo', '0.001'], shell=True, stdout=sb.DEVNULL, stderr=sb.DEVNULL) self.__process.communicate() def __getWeather(self): getURL = '{0}?city={1}'.format(self.__url, self.__city) apiData = requests.get(getURL).json() retList = [apiData[self.__titleStr]] for weather in apiData[self.__loopStr]: tmpData = list(map(lambda x: int(x, 10), weather[self.__dateStr].split('-'))) weatherDate = '{0}年{1}月{2}日'.format(tmpData[0], tmpData[1], tmpData[2]) weatherForecasts = weather[self.__telopStr] retList.append('{0},{1}'.format(weatherDate, weatherForecasts)) return retList # 天気予報取得関数の終了処理 def weatherExitHandler(self): if self.__process.poll() is None: self.__process.terminate() def run(self, wavFile='weather.wav'): listData = self.__getWeather() # 読み上げるテキスト text = ','.join(listData).replace(' ', '') output = CONST_CLASS.WAVE_DIR + wavFile outputList = ['/bin/echo', '"' + str(text) + '"', '|'] outputList.extend(['/usr/local/bin/open_jtalk', '-m', self.__voiceFile, '-ow', output, '-x', self.__dicDir]) # 実行コマンド command = ' '.join(outputList) try: # コマンドの実行 self.__process = sb.Popen(command, shell=True, stdin=sb.PIPE, stdout=sb.PIPE, stderr=sb.PIPE) # 処理の完了待ち self.__process.communicate() except: self.weatherExitHandler() return text
voiceRecognition
メイン処理を実装している部分である.以前導入した「SimpleWebSocketServer」をメインで動作させる.メッセージを受信したら,対象の関数を呼び出し単語解析を実施する.解析結果から赤外線データの送信等の処理を行う.
以下のスクリプトを「voiceRecognition.py」として保存する.
~/juliusKit $ touch voiceRecognition.py ~/juliusKit $ vim voiceRecognition.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # voiceRecognition.py from SimpleWebSocketServer import SimpleWebSocketServer, WebSocket import signal import parseJuliusData, adrsirlib, getWeather import configuration, audioPlayer from VR_ConstClass import CONST_CLASS class voiceRecognitionClass(): def __init__(self): # julius クラスのインスタンス self.__julius = parseJuliusData.parseJuliusDataClass() # configuration クラスのインスタンス self.__configure = configuration.voiceConfigClass() # voice の設定 self.__audio = audioPlayer.audioClass() # weather の設定 self.__weather = getWeather.weatherClass() # 処理開始 def startExecution(self): self.__julius.startThread() # 処理終了 def stopExecution(self): self.__julius.stopThread() # julius の停止 self.__audio.audioExitHandler() # 音声の停止 self.__weather.weatherExitHandler() # 天気予報のデータ生成停止 # 実行用関数 def analysis(self, wordData): # ToDo: スリープモード移行時 if False: retVal = self.__configure.setJuliusState(False) # 動作中だった場合 if retVal: # 停止状態に移行 pass # ToDo: マニュアル操作時 elif False: local_text = wordData sendCmd = self.__configure.getIrCmd(local_text) if sendCmd is not None: # ADRSIR にコマンドを送信 adrsirlib.write(sendCmd) # それ以外 else: retStatus, sendCmd, audioFile = self.__configure.chkCmdExection(wordData) retVal = (retStatus != self.__configure.juliusReturnState[False]) self.__audio.setAudioFile(audioFile) if retVal: outputText = self.__printMsg[retVal] # 天気を読み上げる場合 if retStatus == self.__configure.juliusReturnState['weather']: outputText = self.__weather.run(wavFile=audioFile) self.__audio.playAudio() if sendCmd is not None: # ADRSIR にコマンドを送信 adrsirlib.write(sendCmd) class processStatusClass(): def __init__(self): self.__running = True self.__stopped = False self.__status = self.__running signal.signal(signal.SIGINT, self.changeState) # Ctrl + C の監視 signal.signal(signal.SIGTERM, self.changeState) # kill コマンドの監視 def changeState(self, signum, frame): self.__status = self.__stopped def getStatus(self): return self.__status if __name__ == '__main__': # processStatus クラスのインスタンス procStat = processStatusClass() # voiceRecognitiond クラスのインスタンス vrc = voiceRecognitionClass() # 処理開始 vrc.startExecution() # SimpleWebSocketServer 用のクラス定義 class webSocketProcessClass(WebSocket): def handleMessage(self): vrc.analysis(self.data) # WebSocket 用のサーバのインスタンス生成 server = SimpleWebSocketServer( CONST_CLASS.WEBSOCKET_HOST, CONST_CLASS.WEBSOCKET_PORT, webSocketProcessClass ) # main loop while procStat.getStatus(): server.serveonce() # 処理終了 server.close() vrc.stopExecution()
ここまでのディレクトリ構成を以下に示す.
~/juliusKit |--dictationKit_v4.3.1 |--word.dic |--word.jconf |--grammarKit | |--controller | |--compile.sh | |--mkdfa.pl | |--mkfa | |--utf8_controller.grammar | |--utf8_controller.voca |--outYomi.sh |--word.yomi |--VR_ConstClass.py |--parseJuliusData.py |--webSocketClient.py |--configuration.py |--adrsirlib.py # 追加部分 |--audioPlayer.py # 追加部分 |--getWeather.py # 追加部分 |--voiceRecognitiond.py # 追加部分 |--jsonData | |--TVData.json | |--confParam.json | |--lightData.json |--wavFile |--TVOff.wav |--TVOn.wav |--lightDown.wav |--lightOff.wav |--lightOn.wav |--lightUp.wav |--nightLight.wa
現状,Ctrl + C または,kill コマンドによりプログラムが終了するようになっている.メイン処理の「webSocketProcessClass」というクラスの定義方法がこれで正しいかどうかは分からないが,現状では,この方法でしか WebSocket のサーバを立てることができなかった.他によい方法があればそちらを採用したい.
関数の呼び出し方法等が分かりづらいため,何かしら資料を作成し可視化しておきたい.その前に,この Python スクリプトをデーモン化して,起動時に自動実行するような設定をしようと思っている.
余談
音声認識に記述文法を用いているため,誤認識が時々ある.この認識精度を上げるよい方法はないのだろうか.信頼度とかを使うべきか?
音声認識による赤外線機器の操作 その 6【単語解析編】
どうも,筆者です.
前回は,以下の 3 つを実装した.
- Julius の起動
- Julius からの認識結果の取得
- WebSocket を用いて認識結果を送信
前回までの記事は以下にある.
workspacememory.hatenablog.com
製作状況
製作状況を以下に示す.パーサーの部分は製作が完了している.今回は,単語解析の部分を実装する.

今回の対象
今回対象とする単語解析の部分の構成を以下に示す.

流れとして,受信した単語を単語解析関数に入力し,戻り値として,解析結果,赤外線コマンド,音声ファイルのデータを返すものとする.これらの結果から,音声を流すかどうか,赤外線コマンドを送信するかどうかを決める.
単語の認識方法
さて,問題となる単語の認識方法であるが,ここでは,受信した単語に規定の単語が含まれている場合,その単語が発音されたものとする.具体例を以下に示す.

ここで,必須項目は,解析をするにあたり,必ず含まれている必要がある単語となる.必要項目は,列挙されているもののうち,ひとつでも含めばよいものである.空リストになっているものは,解析対象に含まれないことを意味する.それぞれの単語が見つかった場合の具体的な処理方法も別途データとして用意しておく必要がある.今回は,以下のようなデータを用意した.

起動時に上記のデータを読み込み,処理に利用する.それぞれの項目の働きを以下に示す.
- machine:機器の状態を管理するために利用する(Boolean 型).
- json:読み込む JSON ファイル
- cmd:JSON ファイルに記述されているコマンドのうち,実行するコマンド
- voice:コマンド実行時に再生する音声ファイル
- chkState:現在の状態から次の内部状態を決めるパラメータ
「machine」と「chkState」は関連しており,例えば,テレビがついているのに「テレビつけて」と発声した場合,ほとんどのテレビはオン/オフが同一ボタンであるため,テレビの電源がオフになってしまう.これを防ぐために,現状のテレビの状態を監視しておく必要がある.その際に利用するのが「machine」の部分となる.
また,誤認識防止のため,過去 1 回前までの単語のキーを記憶しておくようにしている.ただ,これに伴い,電気を明るくしたり,(ここにはないが)テレビの音量を上げる場合に必要となる「連続動作」ができなくなる.連続動作の対象となるものは,今回認識した単語を記憶しないようにしたいため,「chkState」を利用する.「chkState」は他にも,テレビがオンのとき「テレビをオンにして」という命令を棄却するのにも利用している.
内部状態を決めるパラメータの定義
現状,「chkState」では,1 Byte のデータを用いて,いくつかの状態を表せるようになっている.その内訳を以下に示す.


これらのうち,予約済みのものを以下に示す.

単語ファイルの更新が追いついていないが,最終的には,「Ok,Google」と話しかけたら認識開始,「ありがとう(仮)」と話しかけたら認識終了としようと考えている.
単語解析コード
上記の設定を実装したものを以下に示す.ここでは,「configuration.py」として保存する.また,実行には,「jsonData」のディレクトリに対象とするデータが追加されている必要がある.
~/juliusKit $ touch configuration.py ~/juliusKit $ vim configuration.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # configuration.py import json from VR_ConstClass import CONST_CLASS class voiceConfigClass(): def __init__(self): # 定数定義(public,結果解析で利用するため,外部から参照可能にしている) self.juliusReturnState = { True: int('0x00', 16), False: int('0x01', 16), 'weather': int('0x02', 16) } # コンフィグ情報のマスク処理用パラメータ self.__maskDict = {'upper': int('0xF0', 16), 'lower': int('0x0F', 16)} # 機器の状態(True: 起動状態,False: 停止状態) self.__state = {'julius': False} # Julius の処理対象 self.__JuliusConfig = { 'invalid': int('0x01', 16), # 無効値 'wakeUp': int('0xFF', 16), # 命令解析開始 'sleep': int('0xF8', 16), # 命令解析終了 'weather': int('0xF0', 16), # 天気予報読み上げ 'init': int('0xF1', 16), # 状態変数の初期化 'active': int('0x10', 16), # 実行中 'stopped': int('0x80', 16), # 停止中 'update': int('0x01', 16), # 状態を更新する 'delPrevWord': int('0x02', 16) # 直前の単語を記憶しない } # 語彙情報(定数) self.__confParamFile = 'confParam.json' # 図に示した「解析時に利用するデータ」が格納されている JSON ファイル self.__vocabInfo = None # 語彙リスト(図に示した「単語認識用データ」) # key: 単語ラベル # val: 語彙候補(mandatory: 必須項目,required: 必要項目) self.__vocabListData = { 'lightOn': { 'mandatory': [str('電気')], 'required': [str('つけて'), str('オン')] }, 'lightOff': { 'mandatory': [str('電気')], 'required': [str('オフ'), str('切って')] }, 'lightUp': { 'mandatory': [str('明るくして')], 'required': [] }, 'lightDown': { 'mandatory': [str('暗くして')], 'required': [] }, 'nightLight': { 'mandatory': [str('こだまにして')], 'required': [] }, 'TVOn': { 'mandatory': [str('テレビ')], 'required': [str('つけて'), str('オン')] }, 'TVOff': { 'mandatory': [str('テレビ')], 'required': [str('オフ'), str('切って')] } } # 作業用変数 self.__jsonData = {} self.__prevWordIdx = '' self.__initConfigData() # 状態変数の初期化 def __initStat(self, invalidList): keyList = [key for key, _ in self.__state.items()] for key in list(set(keyList) - set(invalidList)): self.__state[key] = False # 初期化処理関数 def __initConfigData(self): # config データの取得 jsonFileList = [] machineTypeList = [] # json file から config 情報を読み込む with open(CONST_CLASS.JSON_DIR + self.__confParamFile, 'r') as fin: self.__vocabInfo = json.load(fin) for key in self.__vocabInfo.keys(): useMachine = self.__vocabInfo[key]['machine'].lower() self.__vocabInfo[key]['machine'] = useMachine jsonFileList.append(self.__vocabInfo[key]['json']) machineTypeList.append(useMachine) # 状態変数のキーの追加 for key in list(set(machineTypeList)): self.__state[key] = False # json file の読み込み(list(set(---)) で重複を削除) for targetJsonFile in list(set(jsonFileList)): try: with open(CONST_CLASS.JSON_DIR + targetJsonFile, 'r') as fin: self.__jsonData[targetJsonFile] = json.load(fin) except: # 該当する json file が存在しない場合,処理せず読み飛ばす pass # julius の状態の設定 def setJuliusState(self, status): retVal = self.__state['julius'] self.__state['julius'] = status return retVal # 状態の出力 def getStatus(self): return [(key, self.__state[key]) for key in sorted(list(self.__state.keys()))] # 合致する単語を探す def __findMatchWord(self, wordData): retWordIdx = None # 単語の一覧から合致するパターンを抽出 for key, wordDictList in self.__vocabListData.items(): mandatoryData = wordDictList['mandatory'] requiredData = wordDictList['required'] # 必須項目の単語が含まれているか調査 isExistMandatory = True for targetWord in mandatoryData: if targetWord not in wordData: isExistMandatory = False break # 必要項目の単語が含まれているか調査 if len(requiredData) == 0: isExistRequired = True else: isExistRequired = False for targetWord in requiredData: if targetWord in wordData: isExistRequired = True if isExistMandatory and isExistRequired: retWordIdx = key break return retWordIdx # コマンドの実行可能判定 def chkCmdExection(self, wordData): local_tmpVal = False returnState = self.juliusReturnState[local_tmpVal] retCmd = None wordIdx = self.__findMatchWord(wordData) retAudio = '' # 単語が候補に存在するかつ,前回と同じ単語でない if wordIdx is not None and wordIdx != self.__prevWordIdx: useMachine = self.__vocabInfo[wordIdx]['machine'] useState = int(self.__vocabInfo[wordIdx]['chkState'], 16) useJsonFile = self.__vocabInfo[wordIdx]['json'] useCmd = self.__vocabInfo[wordIdx]['cmd'] tmpAudio = self.__vocabInfo[wordIdx]['voice'] useAudio = {False: '', True: tmpAudio, 'weather': tmpAudio} try: retCmd = self.__jsonData[useJsonFile][useCmd] except: # コマンドが存在しない場合 retCmd = None # 命令解析開始メッセージの場合 if useState == self.__JuliusConfig['wakeUp']: self.setJuliusState(True) local_tmpVal = True self.__prevWordIdx = '' elif self.__state['julius']: # 命令解析終了メッセージの場合 if useState == self.__JuliusConfig['sleep']: self.setJuliusState(False) local_tmpVal = True self.__prevWordIdx = '' # Julius の初期化要求の場合 elif useState == self.__JuliusConfig['init']: # 状態を初期化 self.__initStat(['julius']) local_tmpVal = True self.__prevWordIdx = '' # 天気予報読み上げ要求の場合 elif useState == self.__JuliusConfig['weather']: local_tmpVal = 'weather' self.__prevWordIdx = '' # 無効値でない場合 elif useState != self.__JuliusConfig['invalid']: # 入力コマンドの動作条件を確認し,コマンドを実行するか決める upperInfo = (useState & self.__maskDict['upper']) lowerInfo = (useState & self.__maskDict['lower']) if upperInfo == self.__JuliusConfig['active']: # [期待値]対象機器が動作中 local_tmpVal = self.__state[useMachine] elif upperInfo == self.__JuliusConfig['stopped']: # [期待値]対象機器が停止中 local_tmpVal = not self.__state[useMachine] else: # [期待値]なし で初期化 local_tmpVal = True # コマンドを実行する場合 if local_tmpVal: # 現在の入力単語を記録 self.__prevWordIdx = wordIdx # 下位 4 ビットを確認し処理する if lowerInfo == self.__JuliusConfig['update']: # 状態を反転 self.__state[useMachine] = not self.__state[useMachine] elif lowerInfo == self.__JuliusConfig['delPrevWord']: # 記録した単語を削除 self.__prevWordIdx = '' retAudio = useAudio[local_tmpVal] returnState = self.juliusReturnState[local_tmpVal] return returnState, retCmd, retAudio
自分が利用している「confParam.json」ファイルを以下に示す.
{ "lightOn": { "cmd": "all_light", "machine": "light", "json": "lightData.json", "voice": "lightOn.wav", "chkState": "0x81" }, "lightOff": { "cmd": "light_off", "machine": "light", "json": "lightData.json", "voice": "lightOff.wav", "chkState": "0x11" }, "lightUp": { "cmd": "up", "machine": "light", "json": "lightData.json", "voice": "lightUp.wav", "chkState": "0x12" }, "lightDown": { "cmd": "down", "machine": "light", "json": "lightData.json", "voice": "lightDown.wav", "chkState": "0x12" }, "nightLight": { "cmd": "night_light", "machine": "light", "json": "lightData.json", "voice": "nightLight.wav", "chkState": "0x11" }, "TVOn": { "cmd": "power", "machine": "tv", "json": "TVData.json", "voice": "TVOn.wav", "chkState": "0x81" }, "TVOff": { "cmd": "power", "machine": "tv", "json": "TVData.json", "voice": "TVOff.wav", "chkState": "0x11" } }
長くなってしまったため,main 関数部分と解析結果部分に関しては,次回にまわす.main 関数部分が軸となって動作するため,これまでの関数を利用してスレッドを立ち上げつつ動作する.ここまでのディレクトリ構成を以下に示す.
~/juliusKit |--dictationKit_v4.3.1 |--word.dic |--word.jconf |--grammarKit | |--controller | |--compile.sh | |--mkdfa.pl | |--mkfa | |--utf8_controller.grammar | |--utf8_controller.voca |--outYomi.sh |--word.yomi |--VR_ConstClass.py |--parseJuliusData.py |--webSocketClient.py |--configuration.py # 追加部分 |--jsonData # 追加部分 | |--TVData.json | |--confParam.json | |--lightData.json |--wavFile # 追加部分 |--TVOff.wav |--TVOn.wav |--lightDown.wav |--lightOff.wav |--lightOn.wav |--lightUp.wav |--nightLight.wav
音声認識による赤外線機器の操作 その 5【認識結果パース編】
どうも,筆者です.
前回までで,赤外線操作ができた.ここからは,これらを組み合わせて音声認識結果から赤外線操作を行う.
前回までの記事は以下にある.
workspacememory.hatenablog.com
全体像
ここで,全体像を示しておく.細かい部分や他との関連は,各々のコードを使いつつ確認する.
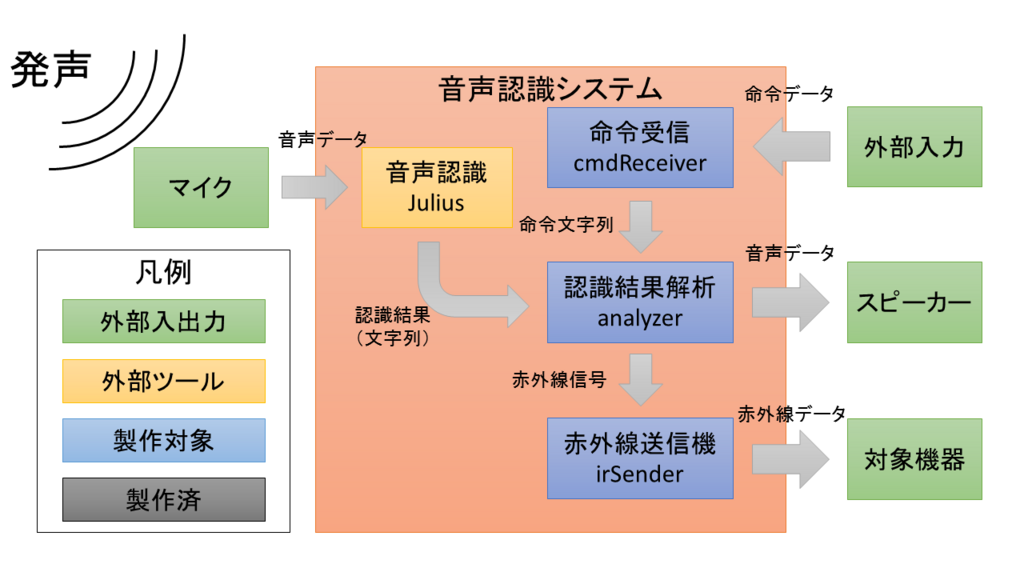
現状の処理の流れとしては,以下のようになる.
- マイクから音声を拾う.
- Julius により音声認識を行い,認識結果を得る.
- 認識結果から,利用する赤外線データを選択する.
- 赤外線データを ADRSIR を用いて外部に出力する.
製作状況
現状では,音声認識結果と赤外線送信は機能としてある.(どちらも,外部ツールに頼っているため,自分で触った部分はほとんどないが...) 今回は,Julius の音声認識結果をパースし,パース結果(単語情報)から赤外線データを選択する部分までを解説する.

認識結果解析の中身
ここでは,認識結果の解析を行うための方法を考える.将来的に別の外部入力から単語情報を入力しても操作できるようにしたいため,以下のように処理を分割する.
- Julius から単語情報を抽出する.
- Julius の起動モードを変更することで,プログラムから結果を受信できる.
- データの受信には socket 通信を用いる.
- 単語情報から赤外線情報を選択する.
- 単語の受信には WebSocket を用いる.
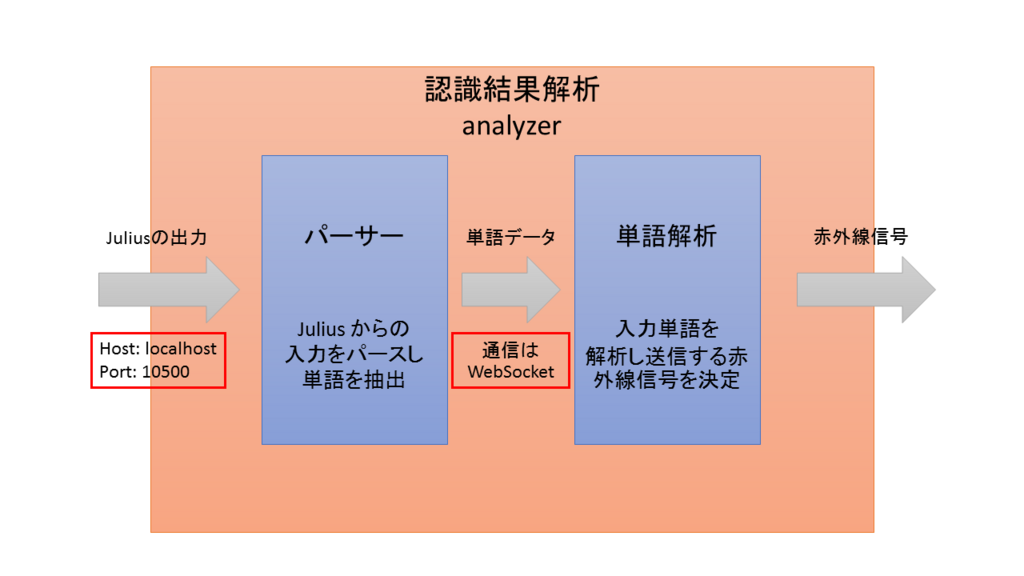
Julius から単語情報を抽出
さて,Python を用いて実際にプログラミングをしていく.これまで,Julius を「-demo」モードで起動してきたが,プログラムからデータを受信するためには,「-module」モードで起動する必要がある.これは単に引数を変更するだけで対応できる. また,「-module」モードで起動した Julius は,localhost の 10500 番に結果を出力する仕様であるため,このホストとポートで入力待ちをすればよい.
グローバル変数の定義
今後,外部ツールや JSON ファイルを読み出すことになるため,必要なパスをグローバル変数として保持しておく.ここでは,以下のようなクラスをもつ Python スクリプトを作成した.ファイル名は「VR_ConstClass.py」である.
~/juliusKit $ touch VR_ConstClass.py ~/juliusKit $ vim VR_ConstClass.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # VR_ConstClass.py class CONST_CLASS: # ========================== # = common const parameter = # ========================== ROOT_DIR = '/home/pi/juliusKit/' # root directory JSON_DIR = ROOT_DIR + 'jsonData/' # json directory WAVE_DIR = ROOT_DIR + 'wavFile/' # wave directory WEBSOCKET_HOST = 'localhost' # WebSocket host name WEBSOCKET_PORT = 10510 # WebSocket port number
ここにあるように,最終的には発音に対し音声で対応できるようにしたいと考えている.
Julius の起動と接続の確立
Julius を起動と Julius に接続するまでの処理を記したスクリプト「parseJuliusData.py」を以下に示す.今後,これに変更を加えていく.
~/juliusKit $ touch parseJuliusData.py ~/juliusKit $ vim parseJuliusData.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # parseJuliusData.py import subprocess as sb import time, socket, threading, select from VR_ConstClass import CONST_CLASS class parseJuliusDataClass(): def __init__(self): # julius ホスト名 self.__juliusHost = 'localhost' # julius ポート番号 self.__juliusPort = 10500 # タイムアウトの最大時間 [sec] self.__maxTimeOut = 20.0 # 受信データサイズ self.__receiveSize = 2048 # Julius サーバ起動コマンド #jconfFile = 'dictationKit_v4.3.1/word.jconf' # 単語認識版 jconfFile = 'grammarKit/control.jconf' # 文法認識版 self.__juliusServerCmd = [ '/usr/local/bin/julius', '-C', CONST_CLASS.ROOT_DIR + jconfFile, '-module', '-nostrip' ] self.__process = None self.__socket = None self.__isRunning = True # Julius の起動 def __wakeUpJuliusServer(self): # Julius Server の起動 self.__process = sb.Popen(self.__juliusServerCmd, stdout=sb.DEVNULL, stderr=sb.DEVNULL) # julius サーバに接続 def __connectionJuliusServer(self, arg_maxTimeout): while True: try: # ソケットの生成 self.__socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.__socket.connect((self.__juliusHost, self.__juliusPort)) break except: self.__socket = None time.sleep(arg_maxTimeout) # 実行用関数 def __parseText(self): local_maxTimeOut = 3 # Julius の起動 self.__wakeUpJuliusServer() # サーバに接続 self.__connectionJuliusServer(local_maxTimeOut)
subprocess や socket の使い方は各自調べてほしい.
WebSocket 利用のための準備
今回は,Julius から受信したデータを単語解析処理に送信する際に,WebSocket を利用するため,コマンドラインで以下をインストールする.
~/juliusKit $ sudo pip3 install git+https://github.com/dpallot/simple-websocket-server.git ~/juliusKit $ sudo pip3 install websocket-client
インストール後,まずは,client 側のコードを作成する.以下のように「webSocketClient.py」として保存する.
~/juliusKit $ touch webSocketClient.py ~/juliusKit $ vim webSocketClient.py # エディタは自分の使いやすいものを利用する
#!/usr/bin/python3 # -*- coding: utf-8 -*- # webSocketClient.py from websocket import create_connection class wsClientClass(): def __init__(self, host, port): self.__connectAddr = 'ws://{0}:{1}/'.format(host, port) def sendMsg(self, message): try: ws = create_connection(self.__connectAddr) ws.send(message) ws.close() except: pass
WebSocket の処理の追加
上記のコードを先程のコードに組み込むと,以下のようになる.
#!/usr/bin/python3 # -*- coding: utf-8 -*- # parseJuliusData.py import subprocess as sb import webSocketClient as wsClient # 追加部分 import time, socket, threading, select from VR_ConstClass import CONST_CLASS class parseJuliusDataClass(): def __init__(self): # julius ホスト名 self.__juliusHost = 'localhost' # julius ポート番号 self.__juliusPort = 10500 # タイムアウトの最大時間 [sec] self.__maxTimeOut = 20.0 # 受信データサイズ self.__receiveSize = 2048 # Julius サーバ起動コマンド #jconfFile = 'dictationKit_v4.3.1/word.jconf' # 単語認識版 jconfFile = 'grammarKit/control.jconf' # 文法認識版 self.__juliusServerCmd = [ '/usr/local/bin/julius', '-C', CONST_CLASS.ROOT_DIR + jconfFile, '-module', '-nostrip' ] self.__process = None self.__socket = None self.__isRunning = True # Julius の起動 def __wakeUpJuliusServer(self): # Julius Server の起動 self.__process = sb.Popen(self.__juliusServerCmd, stdout=sb.DEVNULL, stderr=sb.DEVNULL) # julius サーバに接続 def __connectionJuliusServer(self, arg_maxTimeout): while True: try: # ソケットの生成 self.__socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.__socket.connect((self.__juliusHost, self.__juliusPort)) break except: self.__socket = None time.sleep(arg_maxTimeout) # 実行用関数 def __parseText(self): local_maxTimeOut = 3 # Julius の起動 self.__wakeUpJuliusServer() # サーバに接続 self.__connectionJuliusServer(local_maxTimeOut) # WebSocket Client のインスタンス生成 client = wsClient.wsClientClass( CONST_CLASS.WEBSOCKET_HOST, CONST_CLASS.WEBSOCKET_PORT )
受信処理関数の定義
実際に Julius からデータを受信し処理する部分を以下に示す.
readData = '' while self.__isRunning: # ソケットが読み込み可能状態になるまで待機 inputReady, _, _ = select.select([self.__socket], [], [], self.__maxTimeOut) # 空リストの場合 if len(inputReady) == 0: # タイムアウトしたため,スリープモードへ遷移 # ToDo: タイムアウト処理 pass else: # 読み込み可能状態のソケットが含まれる場合 if self.__socket in inputReady: readData += str(self.__socket.recv(self.__receiveSize).decode('utf-8')) # 「認識結果」のデータがある場合 if '</RECOGOUT>\n.' in readData: wordData = '' for line in readData.split('\n'): # WORD という単語を探す searchStr = 'WORD="' matchIndex = line.find(searchStr) if matchIndex >= 0: # 単語が存在する場合,その単語を抽出 startIdx = matchIndex + len(searchStr) wordData += str(line[startIdx:line.find('"', startIdx)]) # 単語の入力があった場合 if wordData != '': # サーバにデータを送信 client.sendMsg(wordData) readData = ''
受信処理関数のスレッド化
また,これだけが動作するわけではなく,今後作成するほかのプログラムと並列に動作してほしいため,スレッド化する.その処理を加えたものを以下に示す.
#!/usr/bin/python3 # -*- coding: utf-8 -*- # parseJuliusData.py import subprocess as sb import webSocketClient as wsClient import time, socket, threading, select from VR_ConstClass import CONST_CLASS class parseJuliusDataClass(): def __init__(self): # julius ホスト名 self.__juliusHost = 'localhost' # julius ポート番号 self.__juliusPort = 10500 # タイムアウトの最大時間 [sec] self.__maxTimeOut = 20.0 # 受信データサイズ self.__receiveSize = 2048 # Julius サーバ起動コマンド #jconfFile = 'dictationKit_v4.3.1/word.jconf' # 単語認識版 jconfFile = 'grammarKit/control.jconf' # 文法認識版 self.__juliusServerCmd = [ '/usr/local/bin/julius', '-C', CONST_CLASS.ROOT_DIR + jconfFile, '-module', '-nostrip' ] self.__process = None self.__socket = None self.__isRunning = True self.__thread = threading.Thread(target=self.__parseText) # スレッドを開始する def startThread(self): self.__isRunning = True self.__thread.start() # スレッドを停止する def stopThread(self): self.__isRunning = False # 停止イベントを設定 self.__thread.join() # スレッドが停止するのを待つ self.__process.terminate() # サブプロセスを終了する self.__socket.close() # ソケットを閉じる # Julius の起動 def __wakeUpJuliusServer(self): # Julius Server の起動 self.__process = sb.Popen(self.__juliusServerCmd, stdout=sb.DEVNULL, stderr=sb.DEVNULL) # julius サーバに接続 def __connectionJuliusServer(self, arg_maxTimeout): while True: try: # ソケットの生成 self.__socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM) self.__socket.connect((self.__juliusHost, self.__juliusPort)) break except: self.__socket = None time.sleep(arg_maxTimeout) # 実行用関数 def __parseText(self): local_maxTimeOut = 3 # Julius の起動 self.__wakeUpJuliusServer() # サーバに接続 self.__connectionJuliusServer(local_maxTimeOut) # WebSocket Client のインスタンス生成 client = wsClient.wsClientClass( CONST_CLASS.WEBSOCKET_HOST, CONST_CLASS.WEBSOCKET_PORT ) readData = '' while self.__isRunning: # ソケットが読み込み可能状態になるまで待機 inputReady, _, _ = select.select([self.__socket], [], [], self.__maxTimeOut) # 空リストの場合 if len(inputReady) == 0: # タイムアウトしたため,スリープモードへ遷移 # ToDo: タイムアウト処理 pass else: # 読み込み可能状態のソケットが含まれる場合 if self.__socket in inputReady: readData += str(self.__socket.recv(self.__receiveSize).decode('utf-8')) # 「認識結果」のデータがある場合 if '</RECOGOUT>\n.' in readData: wordData = '' for line in readData.split('\n'): # WORD という単語を探す searchStr = 'WORD="' matchIndex = line.find(searchStr) if matchIndex >= 0: # 単語が存在する場合,その単語を抽出 startIdx = matchIndex + len(searchStr) wordData += str(line[startIdx:line.find('"', startIdx)]) # 単語の入力があった場合 if wordData != '': # サーバにデータを送信 client.sendMsg(wordData) readData = ''
ここまでのディレクトリ構成を以下に示す.
~/juliusKit |--dictationKit_v4.3.1 |--word.dic |--word.jconf |--grammarKit | |--controller | |--compile.sh | |--mkdfa.pl | |--mkfa | |--utf8_controller.grammar | |--utf8_controller.voca |--outYomi.sh |--word.yomi |--VR_ConstClass.py # 追加部分 |--parseJuliusData.py # 追加部分 |--webSocketClient.py # 追加部分
長くなったため,一旦ココまでとする.今後,単語解析処理側のプログラムを作成する.